





MLOps na Prática: Pipeline Completo de Machine Learning do Desenvolvimento à Produção
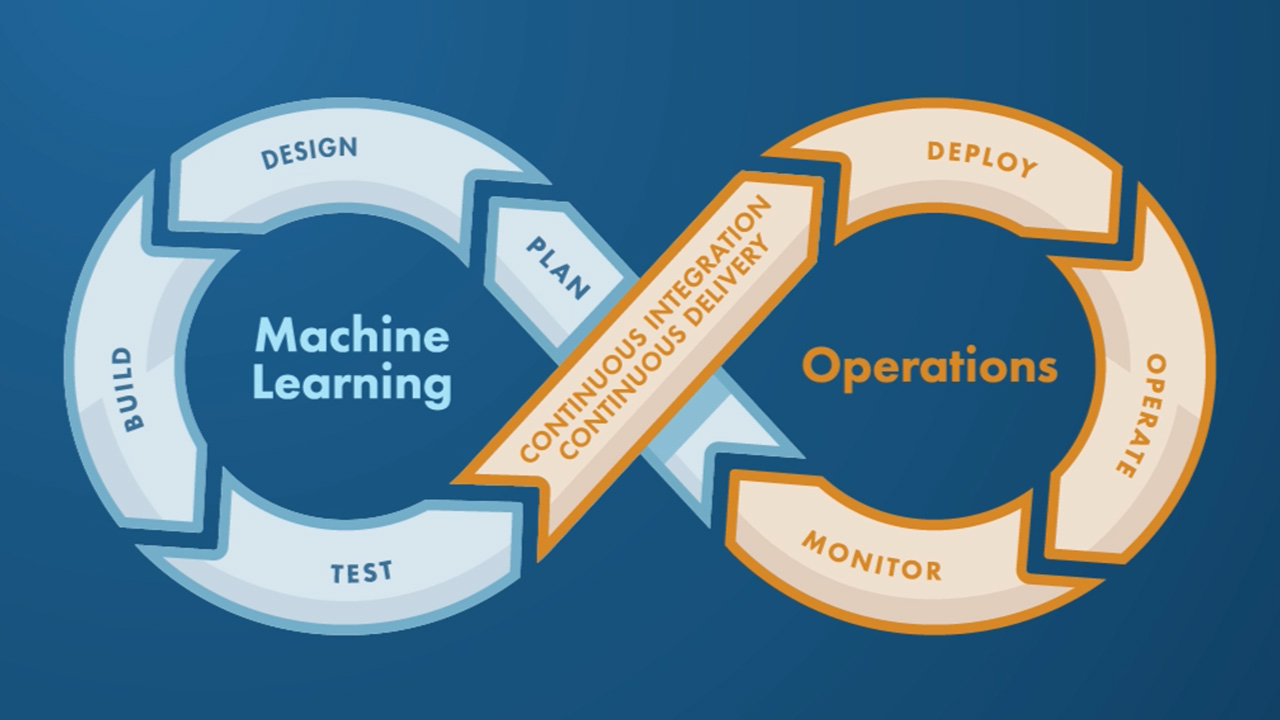
O que é MLOps e Por que sua Empresa Precisa?
MLOps (Machine Learning Operations) é o conjunto de práticas, ferramentas e cultura que une o desenvolvimento de modelos de machine learning com as operações de TI. Inspirado no DevOps tradicional, o MLOps busca automatizar e padronizar o ciclo de vida completo de um modelo — desde a coleta e preparação dos dados até o deploy, monitoramento e retreinamento contínuo.
Em 2026, o mercado de IA vive um paradoxo: nunca foi tão fácil treinar modelos com frameworks modernos como PyTorch, TensorFlow e Hugging Face, mas a taxa de projetos que efetivamente chegam à produção ainda gira em torno de 20%. O gargalo não está mais no algoritmo — está na operação. É aí que o MLOps entra.
Pilares do MLOps
O MLOps se sustenta em quatro pilares fundamentais que garantem que modelos sejam confiáveis, rastreáveis e fáceis de atualizar:
- Reprodutibilidade: todo experimento deve ser reproduzível — mesmo meses depois. Isso exige versionamento de dados, código, hiperparâmetros e ambiente.
- Versionamento: dados, features, modelos e configurações precisam de controle de versão dedicado. Git para código, DVC ou LakeFS para dados, MLflow para experimentos.
- Automação de Pipelines: o fluxo de dados, treino, validação e deploy deve ser automatizado e orquestrado, eliminando etapas manuais e reduzindo erros.
- Monitoramento Contínuo: um modelo em produção não é um artefato estático — ele degrada com o tempo (drift). Monitorar métricas de performance, dados de entrada e saída é essencial.
Ciclo de Vida de um Projeto MLOps
Vamos percorrer as etapas de um pipeline MLOps moderno, usando ferramentas open-source amplamente adotadas:
1. Versionamento de Dados
Antes de qualquer modelo, os dados precisam ser versionados. DVC (Data Version Control) permite rastrear datasets, splits de treino/teste e transformações como se fossem branches de git:
# Inicializar DVC em um repositório existente
git init
dvc init
# Adicionar dataset ao controle de versão
dvc add data/dataset_raw.csv
git add data/dataset_raw.csv.dvc .gitignore
git commit -m "chore: versiona dataset bruto v1.0"
# Criar uma nova versão do dataset
dvc checkout # volta para versão anterior
# Após modificar os dados...
dvc add data/dataset_raw.csv
git commit -m "feat: adiciona novos registros ao dataset v1.1"2. Experimentação e Rastreamento
Cada experimento de ML precisa ser registrado. O MLflow é a ferramenta mais difundida para esse propósito, permitindo rastrear hiperparâmetros, métricas, artefatos e o próprio código do modelo:
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score
mlflow.set_tracking_uri("http://mlflow.craftxp.com:5000")
mlflow.set_experiment("churn-prediction")
with mlflow.start_run():
# Hiperparâmetros
n_estimators = 200
max_depth = 10
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
# Treinamento
model = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
random_state=42
)
model.fit(X_train, y_train)
# Métricas
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
mlflow.log_metric("accuracy", acc)
mlflow.log_metric("precision", prec)
# Registrar o modelo
mlflow.sklearn.log_model(model, "model")
print(f"Run ID: {mlflow.active_run().info.run_id}")3. Pipeline de Feature Engineering Automatizado
Features devem ser calculadas de forma consistente entre treino e inferência. Ferramentas como Feature Store (Feast, Hopsworks) centralizam a definição e o cálculo de features:
# Exemplo com Feast — Definição de Feature Views
from datetime import timedelta
from feast import Entity, FeatureView, Field, FileSource
from feast.types import Float32, Int32
# Fonte dos dados
transaction_source = FileSource(
path="s3://craftxp-data/transactions.parquet",
timestamp_field="event_timestamp",
)
# Entidade
customer = Entity(
name="customer_id",
join_keys=["customer_id"],
description="Identificador único do cliente",
)
# Feature View
customer_features = FeatureView(
name="customer_transaction_features",
entities=[customer],
ttl=timedelta(days=7),
schema=[
Field(name="avg_transaction_value_7d", dtype=Float32),
Field(name="transaction_count_30d", dtype=Int32),
Field(name="recency_days", dtype=Int32),
],
source=transaction_source,
)4. Testes de Validação de Modelo
Antes de levar um modelo à produção, ele precisa passar por uma suíte de validações automatizadas. Ferramentas como Great Expectations (para dados) e testes unitários de ML garantem qualidade:
import great_expectations as ge
import numpy as np
# Validar dados de entrada
df = ge.read_csv("batch_inference_data.csv")
# Expectativas básicas
df.expect_column_values_to_not_be_null("customer_id")
df.expect_column_values_to_be_between("age", 0, 120)
df.expect_column_values_to_be_in_set(
"plan_type", ["basic", "premium", "enterprise"]
)
# Validar performance do modelo contra baseline
def validate_model_performance(y_true, y_pred):
accuracy = np.mean(y_true == y_pred)
assert accuracy > 0.85, f"Acurácia {accuracy:.3f} abaixo do baseline 0.85"
print(f"✓ Modelo aprovado — acurácia: {accuracy:.3f}")5. Deploy Contínuo com CI/CD
O deploy de modelos segue o mesmo princípio do DevOps tradicional. Aqui está um pipeline usando GitHub Actions para automatizar todo o fluxo:
# .github/workflows/ml-pipeline.yml
name: MLOps Pipeline
on:
push:
branches: [main]
paths:
- "models/**"
- "features/**"
- "notebooks/**"
jobs:
train-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Python
uses: actions/setup-python@v5
with:
python-version: "3.12"
- name: Instalar dependências
run: |
pip install -r requirements.txt
pip install mlflow dvc feast
- name: Baixar dados versionados
run: dvc pull
- name: Treinar modelo
run: |
python train.py \
--experiment churn-prediction \
--run-id $(date +%s)
- name: Validar modelo
run: python validate.py
- name: Registrar modelo no MLflow Registry
run: |
python register_model.py \
--stage "Staging"
- name: Deploy para staging
run: |
python deploy.py \
--target staging \
--model-uri $(cat model_uri.txt)6. Monitoramento em Produção
Um modelo em produção precisa ser monitorado continuamente. Duas métricas críticas são o data drift (mudança na distribuição dos dados de entrada) e o concept drift (mudança na relação entre features e target):
# Monitoramento de drift com Evidently AI
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
# Dados de referência (treino) vs dados atuais (produção)
reference = pd.read_parquet("data/train_data.parquet")
current = pd.read_parquet("data/production_batch.parquet")
report = Report(metrics=[DataDriftPreset()])
report.run(reference_data=reference, current_data=current)
# Extrair resumo do drift
drift_summary = report.as_dict()
drift_score = drift_summary["metrics"][0]["result"]["drift_by_columns"]
alerts = []
for col, metrics in drift_score.items():
if metrics["drift_detected"]:
alerts.append(f"⚠️ Drift detectado na feature '{col}'")
print(f"[ALERTA] Drift detectado em: {col}")
if len(alerts) > 3:
print("[CRÍTICO] Múltiplos drifts detectados — acionar retreinamento!")Arquitetura de um Pipeline MLOps Completo
Uma arquitetura de referência para MLOps em 2026 combina estas camadas:
┌─────────────────────────────────────────────────────┐
│ DATA LAYER │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │ Data Lake│ │ Feature │ │ Data Quality │ │
│ │(S3/ MinIO)│ │ Store │ │ (Great Exp.) │ │
│ └──────────┘ │ (Feast) │ └──────────────────┘ │
│ └──────────┘ │
├─────────────────────────────────────────────────────┤
│ MODEL LAYER │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │ MLflow │ │ Model │ │ Container Registry│ │
│ │ Tracking │ │ Registry │ │ (Docker Hub) │ │
│ └──────────┘ └──────────┘ └──────────────────┘ │
├─────────────────────────────────────────────────────┤
│ DEPLOYMENT LAYER │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │Kubernetes│ │ KServe │ │ API Gateway │ │
│ │(EKS/GKE) │ │(Inference)│ │ (Kong/Nginx) │ │
│ └──────────┘ └──────────┘ └──────────────────┘ │
├─────────────────────────────────────────────────────┤
│ MONITORING LAYER │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │Evidently │ │ Prometheus│ │ Grafana │ │
│ │ AI │ │ Metrics │ │ Dashboards │ │
│ └──────────┘ └──────────┘ └──────────────────┘ │
└─────────────────────────────────────────────────────┘Ferramentas Essenciais do Ecossistema MLOps
- MLflow: gerenciamento do ciclo de vida — tracking, registry, deployment. Padrão de facto para experimentação.
- DVC (Data Version Control): versionamento de datasets e pipelines de dados com integração Git.
- Feast: Feature Store open-source para definição, descoberta e servimento consistente de features.
- Great Expectations: validação e documentação de dados com expectativas declarativas.
- Evidently AI: monitoramento de drift, qualidade de dados e performance de modelos.
- KServe: inferência serverless em Kubernetes com auto-scaling, canary deployments e explainability.
- ZenML / Kedro: frameworks de orquestração de pipelines de ML com boas práticas incorporadas.
- Prometheus + Grafana: monitoramento de infraestrutura e dashboards de saúde dos modelos.
Pitfalls Comuns em MLOps (e Como Evitá-los)
- Treino vs Inferência inconsistentes: features calculadas de forma diferente entre treino e produção. Solução: Feature Store com pipeline único de transformação.
- Modelo funciona, mas ninguém confia: falta de rastreabilidade e linhagem dos dados. Solução: MLflow Registry + DVC para rastrear cada artefato.
- Drift silencioso: modelo degrada sem ninguém perceber por semanas. Solução: dashboards de monitoramento com alertas automáticos no Slack/Email.
- Deploy manual quebrou a API: versão errada do modelo ou dependências incompatíveis. Solução: CI/CD automatizado com testes de integração e canary deployments.
- Dados sensíveis vazam para logs: PII nos datasets de treino aparece nas inferências. Solução: pipelines de anonimização e validação de privacidade antes do treino.
MLOps em Equipes Pequenas
Você não precisa de uma plataforma corporativa cara para começar. Para times pequenos ou startups, uma stack enxuta funciona muito bem:
# Stack MLOps Minimalista para Começar
#
# 1. Versionamento: Git + DVC (storage: Google Drive ou S3)
# 2. Experimentos: MLflow Tracking (localhost ou free tier Databricks)
# 3. Pipelines: Python scripts + Makefile + cron
# 4. Deploy: FastAPI + Docker + Railway/Render
# 5. Monitoramento: Evidently AI (biblioteca local) + scripts periódicos
# 6. CI/CD: GitHub Actions (gratuito para repositórios públicos)
#
# Custo total: ~$0/mês para começarConclusão
MLOps não é um luxo — é uma necessidade para qualquer equipe que queira levar modelos de machine learning à produção com confiança. As práticas e ferramentas apresentadas aqui formam a base de um pipeline maduro que cobre desde o versionamento de dados até o monitoramento contínuo.
Comece pequeno: implemente o MLflow Tracking nos seus próximos experimentos, adicione DVC para versionar datasets e automatize uma validação simples com Great Expectations. Cada camada adicionada reduz o risco de surpresas desagradáveis em produção e aumenta a confiança — tanto da equipe técnica quanto dos stakeholders de negócio.
Lembre-se: um modelo em produção que não é monitorado é um modelo que vai falhar. E com MLOps, você saberá exatamente quando, por que e como corrigir.
