





XGBoost, LightGBM e CatBoost: Gradient Boosting na Prática para Machine Learning de Alto Desempenho
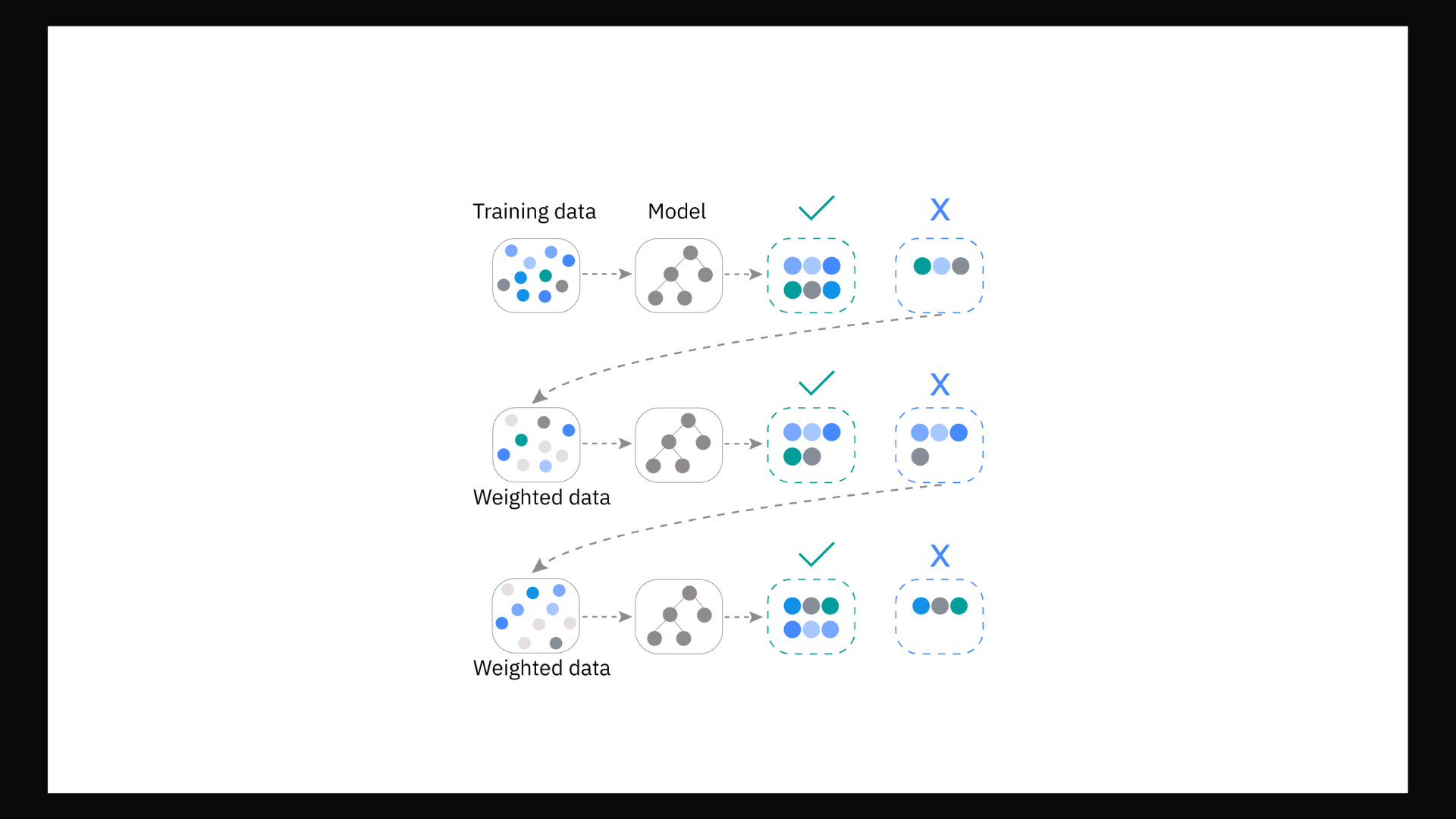
O que é Gradient Boosting?
Gradient Boosting é uma das técnicas mais poderosas e populares de Machine Learning supervisionado. Diferente de modelos tradicionais que treinam um único algoritmo, o Gradient Boosting constrói um conjunto (ensemble) de árvores de decisão fracas, onde cada nova árvore tenta corrigir os erros da combinação anterior. O resultado é um modelo altamente preciso e robusto, capaz de capturar relações complexas nos dados sem exigir escala ou normalização das features.
Nos últimos anos, três frameworks dominaram o ecossistema: XGBoost, LightGBM e CatBoost. Cada um tem suas particularidades, vantagens e cenários ideais de uso. Este guia vai te ajudar a entender as diferenças e escolher o melhor para cada problema.
XGBoost: O Pioneiro que Conquistou o Kaggle
Lançado em 2014 por Tianqi Chen, o XGBoost (eXtreme Gradient Boosting) foi o framework que popularizou o Gradient Boosting no mundo da Ciência de Dados. Durante anos, foi a ferramenta preferida de vencedores de competições no Kaggle, sendo utilizado em mais de 50% das soluções campeãs.
Principais características:
- Regularização integrada: XGBoost inclui penalidades L1 (Lasso) e L2 (Ridge) na função de perda, reduzindo overfitting de forma nativa — algo que árvores de decisão tradicionais não oferecem
- Processamento paralelo: Utiliza todos os núcleos da CPU para construir árvores em paralelo, acelerando significativamente o treinamento
- Handling de missing values: Aprende automaticamente a direção ideal para valores nulos durante o treinamento, sem necessidade de imputação manual
- Cross-validation integrada: Permite realizar validação cruzada diretamente durante o treinamento com uma única linha de código
- Suporte a GPU: Treinamento acelerado por GPU para datasets de grande porte
import xgboost as xgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Carregar dados
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target, test_size=0.2, random_state=42
)
# Criar e treinar modelo XGBoost
model = xgb.XGBClassifier(
n_estimators=200,
max_depth=6,
learning_rate=0.05,
subsample=0.8,
colsample_bytree=0.8,
reg_lambda=1.0,
eval_metric='logloss'
)
model.fit(X_train, y_train)
# Avaliar
y_pred = model.predict(X_test)
print(f'Acurácia: {accuracy_score(y_test, y_pred):.4f}')
# Importância das features
importances = model.feature_importances_
for name, imp in zip(data.feature_names, importances):
if imp > 0.05:
print(f'{name}: {imp:.3f}')LightGBM: Velocidade e Eficiência para Grandes Volumes
Desenvolvido pela Microsoft em 2017, o LightGBM foi criado para resolver uma limitação importante do XGBoost: a escalabilidade para datasets com milhões de linhas e centenas de features. Enquanto o XGBoost cresce as árvores nível por nível (level-wise), o LightGBM adota uma abordagem folha por folha (leaf-wise), escolhendo a folha com maior ganho para expandir a cada iteração.
Isso resulta em árvores mais profundas e assimétricas, que convergem mais rapidamente. O LightGBM pode ser de 5 a 10 vezes mais rápido que o XGBoost em datasets grandes, consumindo menos memória.
Diferenciais importantes:
- GOSS (Gradient-based One-Side Sampling): Técnica proprietária que amostra os dados de forma inteligente, dando mais peso às instâncias com gradientes maiores (onde o modelo mais erra)
- EFB (Exclusive Feature Bundling): Agrupa features esparsas mutualmente exclusivas, reduzindo a dimensionalidade sem perder informação
- Suporte nativo a categorias: Aceita features categóricas diretamente, sem necessidade de one-hot encoding
- Menor consumo de memória: Ideal para ambientes com recursos limitados ou processamento em lote
import lightgbm as lgb
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
# Preparar dados
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target, test_size=0.2, random_state=42
)
# Dataset LightGBM
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_test, y_test, reference=lgb_train)
# Parâmetros
params = {
'objective': 'binary',
'metric': 'auc',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': -1
}
# Treinar
model = lgb.train(
params,
lgb_train,
num_boost_round=200,
valid_sets=[lgb_train, lgb_valid],
callbacks=[lgb.early_stopping(stopping_rounds=20)]
)
# Avaliar
y_pred_prob = model.predict(X_test)
print(f'AUC-ROC: {roc_auc_score(y_test, y_pred_prob):.4f}')
print(f'Melhor iteração: {model.best_iteration}')CatBoost: O Poder das Features Categóricas sem Pré-processamento
Criado pela Yandex em 2017, o CatBoost (Categorical Boosting) se destaca pelo tratamento nativo e sofisticado de variáveis categóricas. Enquanto XGBoost e LightGBM exigem codificação manual (one-hot, label encoding), o CatBoost implementa técnicas avançadas como target encoding com ordenação temporal e combinações automáticas de categorias.
Outra inovação fundamental é o Ordered Boosting, uma variação do Gradient Boosting tradicional que reduz o viés de target leakage — um problema comum onde o modelo "aprende" o target indiretamente durante o treinamento.
Vantagens exclusivas:
- Zero pré-processamento: Funciona diretamente com dados categóricos, textos e até embeddings — sem one-hot, sem label encoding, sem normalização
- Ordered Boosting: Algoritmo proprietário que elimina o viés de target leakage, comum em outros frameworks
- Suporte a texto: Pode processar colunas de texto diretamente, extraindo features de forma automática
- Resultados consistentes: Produz modelos estáveis mesmo com hyperparâmetros padrão, reduzindo a necessidade de tuning extensivo
- Predições com explicações: Métodos integrados de SHAP Values para explicabilidade dos resultados
from catboost import CatBoostClassifier
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
# Criar dataset com features categóricas
df = pd.DataFrame({
'idade': [25, 34, 45, 23, 52, 31],
'cidade': ['SP', 'RJ', 'BH', 'SP', 'POA', 'RJ'],
'profissao': ['engenheiro', 'médico', 'engenheiro', 'advogado', 'médico', 'advogado'],
'renda': [5000, 12000, 8000, 4000, 15000, 6000],
'target': [0, 1, 1, 0, 1, 0]
})
# Features categóricas — identificar pelo índice ou nome
cat_features = ['cidade', 'profissao']
X = df.drop('target', axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# CatBoost não precisa de encoding!
model = CatBoostClassifier(
iterations=200,
learning_rate=0.05,
depth=6,
cat_features=cat_features,
verbose=50
)
model.fit(X_train, y_train)
# Avaliar
y_pred = model.predict(X_test)
print(f'F1-Score: {f1_score(y_test, y_pred):.4f}')
# Importância das features
feature_importances = model.get_feature_importance()
for name, imp in zip(X.columns, feature_importances):
print(f'{name}: {imp:.2f}')Comparação Direta: Qual Usar em Cada Cenário?
A escolha entre os três frameworks depende do seu problema, dos seus dados e dos seus requisitos de performance:
- XGBoost é a escolha mais equilibrada e madura. Funciona bem na maioria dos cenários, tem a maior comunidade e documentação, e é a opção mais segura se você não tem certeza por onde começar. É ideal para competições Kaggle e projetos onde a precisão é mais importante que a velocidade de treinamento.
- LightGBM é a melhor opção quando você tem datasets muito grandes (milhões de linhas) e precisa de treinamento rápido. É excelente para pipelines de produção que rodam diariamente e para problemas de alta dimensionalidade com muitas features esparsas.
- CatBoost é imbatível quando seus dados têm muitas features categóricas ou texto. Se você trabalha com bases de dados do mundo real — como dados de CRM, vendas, RH ou atendimento ao cliente — o CatBoost vai te poupar horas de pré-processamento e ainda entregar resultados superiores.
Na prática, muitos profissionais treinam os três modelos e selecionam o melhor com base em validação cruzada. Uma estratégia comum é usar o LightGBM para exploração rápida, o CatBoost para dados mistos (numéricos + categóricos) e o XGBoost para o modelo final em problemas puramente numéricos.
Otimização de Hyperparâmetros
Para extrair o máximo de cada framework, a otimização de hyperparâmetros é essencial. Ferramentas como Optuna, Hyperopt e GridSearchCV do scikit-learn podem ser integradas facilmente:
import optuna
import xgboost as xgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import cross_val_score
# Carregar dados
data = load_breast_cancer()
X, y = data.data, data.target
def objective(trial):
params = {
'n_estimators': trial.suggest_int('n_estimators', 100, 500),
'max_depth': trial.suggest_int('max_depth', 3, 10),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.3, log=True),
'subsample': trial.suggest_float('subsample', 0.6, 1.0),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.6, 1.0),
'reg_lambda': trial.suggest_float('reg_lambda', 0.01, 10.0, log=True),
'reg_alpha': trial.suggest_float('reg_alpha', 0.01, 10.0, log=True),
}
model = xgb.XGBClassifier(**params, eval_metric='logloss', use_label_encoder=False)
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
return scores.mean()
# Executar busca
study = optuna.create_study(direction='maximize', study_name='XGBoost Optimization')
study.optimize(objective, n_trials=50)
print(f'Melhores parâmetros: {study.best_params}')
print(f'Melhor acurácia: {study.best_value:.4f}')Casos de Uso Reais
Os frameworks de Gradient Boosting são utilizados em produção por empresas de todos os portes:
- Instituições financeiras: Detecção de fraudes em tempo real com XGBoost, analisando milhares de transações por segundo e identificando padrões suspeitos com alta precisão
- E-commerce: Sistemas de recomendação com LightGBM que processam milhões de interações de usuários para sugerir produtos personalizados em milissegundos
- Saúde: Predição de risco de doenças com CatBoost usando dados mistos (exames numéricos + histórico médico categórico + notas clínicas em texto)
- Agronegócio: Previsão de safras combinando dados meteorológicos, de solo e históricos com Gradient Boosting para otimizar plantio e colheita
- Telecomunicações: Modelos de churn prediction que identificam clientes com maior risco de cancelamento, permitindo ações preventivas de retenção
Conclusão
XGBoost, LightGBM e CatBoost representam o estado da arte em Machine Learning baseado em árvores. Dominar esses três frameworks é uma habilidade essencial para qualquer cientista de dados que queira construir modelos preditivos de alto desempenho no mundo real.
Não existe uma ferramenta universalmente superior — cada uma brilha em cenários diferentes. O verdadeiro diferencial está em conhecer as forças de cada uma e saber aplicá-las estrategicamente. Comece experimentando com os hyperparâmetros padrão, compare os resultados com validação cruzada, e só então invista tempo em otimização fina.
Que tal abrir um notebook hoje mesmo e testar os três frameworks no seu dataset favorito? Os resultados podem te surpreender!
